某售房平台的房价爬虫
今天某同学因为研究需要,想爬某个售房平台的房价数据做研究用,但由于反爬没能拿到。我拿过链接看了看,发现这种反爬技术比较新奇。
通过 Chrome 浏览器的开发者工具查看,发现这个网站是把房价数据通过图片的形式发送到浏览器的。
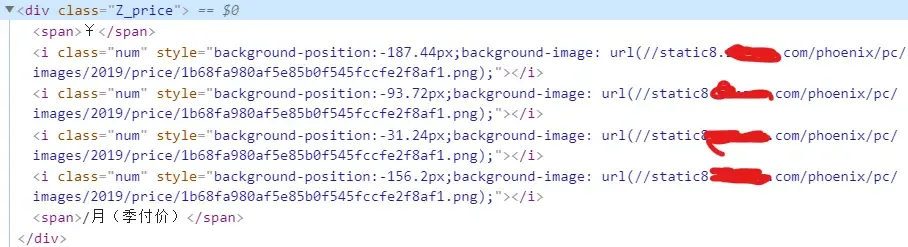
打开链接会发现是这样一张图片,通过控制 background-position 属性配合其他的 css 文件可以实现截取某个数字展示的效果。有点像滚轮密码锁。


并且在不同时候刷新页面,得到的图片是不同的,进一步增加了爬虫的复杂度。
监控页面的节点变化发现,目标节点部分从服务器发送到浏览器便一直都保持不变,这意味着从数据到图片的转换是在服务器后台完成的,而不是前端浏览器的 Javascript 脚本控制的。
(这会给后端服务器带来比较大的压力吧,又要定期生成随机顺序的图片,又要建立数据和图片的关联关系,当然不排除其图片是已经生成好的,只是通过哈希索引进行查找出来罢了,如此一来数据和图片的对应关系相对来说也就不是那么损耗性能的了,用模板来生成 html 压力其实也还好)。
这就切断了通过爬虫直接得到数值型数据的可能性了。
目前没有想到更好的解决方案,有一种很蠢的方法就是把 background-image 和 background-position 都爬下来,然后根据 background-position 裁剪图片的一部分拿去做 OCR 识别出来的结果再和这个房子的信息一起保存下来。