快速认识线程
现代操作系统几乎都支持多任务,对计算机来说每个任务就是一个进程(Process),每个进程中必须要有一个线程(Thread)是在运行中的,有时线程也称为轻量级的进程。每个线程都有自己的局部变量表、程序计数器以及生命周期等。
快速创建一个线程
public static void main(String[] args) {
//通过匿名内部类的方式创建线程,并且重写其中的run方法
new Thread() { //①
@Override
public void run() {
enjoyMusic();
}
}.start(); //②
browseNews();
}创建线程必须要两步:
- 创建一个
Thread实例,并重写其run方法; - 调用其
start()方法,该方法不会阻塞主线程;
程序启动后我们可以使用 jstack 工具查看线程快照,线程快照中包含每个线程瞬时的方法调用栈,当程序死锁是可以使用该工具分析线程死锁的原因;
对以上程序我们会看到不止两个线程: Thread-0 是我们启动的线程, main 是主线程。另外还有一些守护线程,比如垃圾回收线程、 RMI 线程等。
线程的生命周期
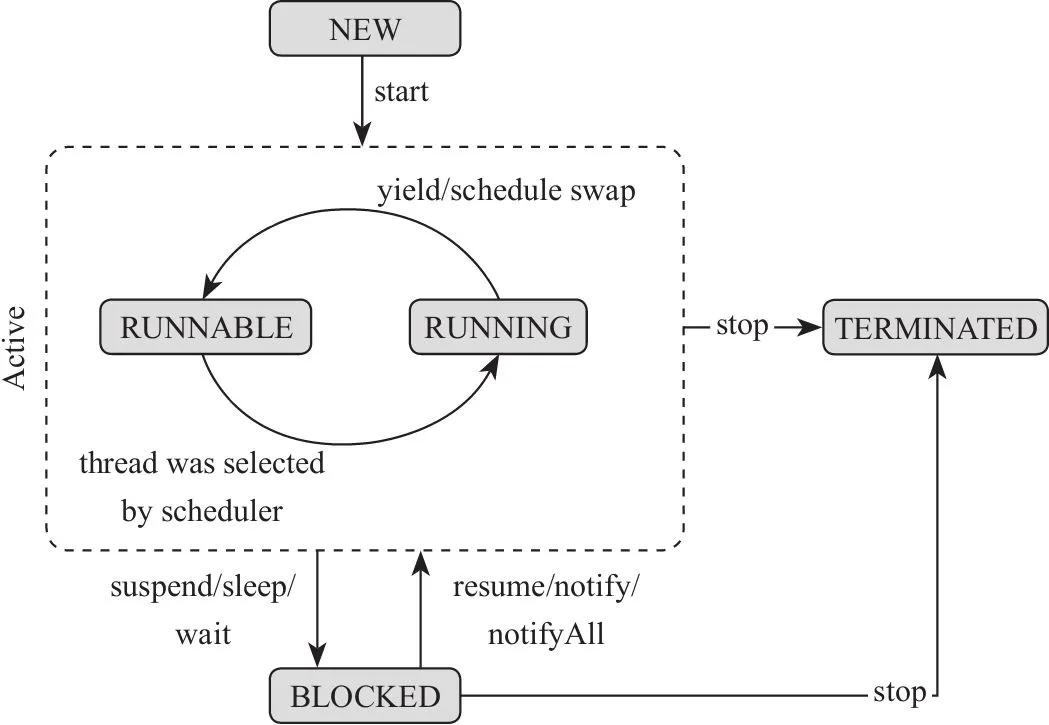
线程的生命周期大致分为五个阶段:
- NEW:没有调用
start()方法启动该线程,那么线程的状态为 NEW 状态; - RUNNABLE:NEW 状态通过
start()方法进入 RUNNABLE 状态,这个状态说明线程具备执行的资格,但是并没有真正地执行起来而是在等待 CPU 的调度; - RUNNING:一旦 CPU 通过轮询或者其他方式从任务可执行队列中选中了线程,此时它才能真正地执行自己的逻辑代码,进入 RUNNING 状态。该状态的线程有三种去向:
- 直接进入 TERMINATED 状态,比如调用 JDK 已经不推荐使用的
stop()方法或者判断某个逻辑标识; - 进入 BLOCKED 状态,比如调用了
sleep(),或者wait()方法而加入了waitSet中; - 进行某个阻塞的 IO 操作,比如因网络数据的读写而进入了 BLOCKED 状态;
- 获取某个锁资源,从而加入到该锁的阻塞队列中而进入了 BLOCKED 状态;
- 由于 CPU 的调度器轮询使该线程放弃执行,进入 RUNNABLE 状态;
- 线程主动调用
yield()方法,放弃 CPU 执行权,进入 RUNNABLE 状态。
- 直接进入 TERMINATED 状态,比如调用 JDK 已经不推荐使用的
- BLOCKED:BLOCKED 即阻塞状态,进入阻塞状态的方法如上述。线程在 BLOCKED 状态中可以切换至如下几个状态:
- 直接进入 TERMINATED 状态,比如调用 JDK 已经不推荐使用的
stop()方法或者意外死亡(JVM Crash); - 线程阻塞的操作结束,比如读取了想要的数据字节进入到 RUNNABLE 状态;
- 线程完成了指定时间的休眠,进入到了 RUNNABLE 状态;
- Wait 中的线程被其他线程
notify()/notifyall()唤醒,进入 RUNNABLE 状态; - 线程获取到了某个锁资源,进入 RUNNABLE 状态;
- 线程在阻塞过程中被打断,比如其他线程调用了
interrupt()方法,进入 RUNNABLE 状态
- 直接进入 TERMINATED 状态,比如调用 JDK 已经不推荐使用的
- TERMINATED:TERMINATED 是一个线程的最终状态,在该状态中线程将不会切换到其他任何状态,线程进入 TERMINATED 状态,意味着该线程的整个生命周期都结束了;
- 线程运行正常结束,结束生命周期;
- 线程运行出错意外结束;
- JVM Crash,导致所有的线程都结束;
start 方法的细节
start() 方法内部调用的是 start0 方法, start0 方法是一个 JNI 方法,重写的 run 方法是在 start0 方法内部调用的。
public synchronized void start() {
if (threadStatus != 0)
throw new IllegalThreadStateException();
group.add(this);
boolean started = false;
try {
start0();
started = true;
} finally {
try {
if (!started) {
group.threadStartFailed(this);
}
} catch (Throwable ignore) {
}
}
}从源码我们可以看出:
- Thread 被构造后的 NEW 状态,事实上 threadStatus 这个内部属性为 0;
- 不能两次启动 Thread ,否则就会出现 IllegalThreadStateException 异常;
- 线程启动后将会被加入到一个 ThreadGroup 中;
- 一个线程生命周期结束,也就是到了 TERMINATED 状态,再次调用 start 方法是不允许的,也就是说 TERMINATED 状态是没有办法回到 RUNNABLE/RUNNING 状态的;
Thread 类中的 run 方法和 start 方法使用了 模板设计模式 ,由父类编写算法结构代码,子类实现逻辑细节,这样做的好处是,程序结构由父类控制,并且是 final 修饰的,不允许被重写,子类只需要实现想要的逻辑任务即可。
public class TemplateMethod {
public final void print(String message) {
System.out.println("################");
wrapPrint(message);
System.out.println("################");
}
protected void wrapPrint(String message) {
}
public static void main(String[] args) {
TemplateMethod t1 = new TemplateMethod(){
@Override
protected void wrapPrint(String message) {
System.out.println("*"+message+"*");
}
};
t1.print("Hello Thread");
TemplateMethod t2 = new TemplateMethod(){
@Override
protected void wrapPrint(String message) {
System.out.println("+"+message+"+");
}
};
t2.print("Hello Thread");
}
}Runnable 接口
为了分离线程的控制和业务逻辑,Java 提供了 Runnable 接口,开发者可以将线程的业务逻辑使用 Runnable 的 run 方法封装。
这种线程控制和业务逻辑分离的思想,与设计模式中的策略模式很相似(如果具体的业务逻辑看作是线程运行使用的策略)。这种设计使得 Thread 和 Runable 职责分明、功能单一。
深入 Thread
线程命名
对于没有命名的线程构造函数,比如默认的构造方法 new Thread() 和 new Thread(Runnable target) 方法,使用这些方法声明一个线程时,会使用 Thread- 加一个自增的数字作为线程的名字,这个自增的数字将在 JVM 进程中不断自增。实践中,建议在创建线程的时候使用带有线程名的构造函数,或者在线程启动之前通过 setName() 方法设置线程名。
线程间的父子关系
Thread 的所有构造函数,最终都会去调用一个静态方法 init,任何一个线程都会有一个父线程:
private void init(ThreadGroup g, Runnable target, String name,
long stackSize, AccessControlContext acc) {
if (name == null) {
throw new NullPointerException("name cannot be null");
}
this.name = name.toCharArray();
Thread parent = currentThread(); //获取当前线程作为父线程
SecurityManager security = System.getSecurityManager();
// ...
}currentThread() 是获取当前线程,在线程生命周期中,我们说过线程的最初状态为 NEW ,没有执行 start 方法之前,它只能算是一个 Thread 的实例,并不意味着一个新的线程被创建,因此 currentThread() 代表的将会是创建它的那个线程。
- 一个线程的创建肯定是由另一个线程完成的。
- 被创建线程的父线程是创建它的线程。
main 函数所在的线程是由 JVM 创建的,也就是 main 线程,那就意味着我们前面创建的所有线程,其父线程都是 main 线程。
ThreadGroup
ThreadGroup 线程组,如果没有使用线程组创建线程,那么新线程默认会被加入 main 线程的线程组 main 中。默认设置中,子线程和主线程有同样的的 优先级 ,同样的 daemon ,也可以看作是子线程继承了父线程的这些属性。
线程与 JVM 虚拟机栈
在 Thread 的构造函数中,有一个带有 stackSize 参数的,这个参数越大,代表着线程能递归调用的深度就越深, stackSize 越小就越能创建更多的线程;这个参数一般不用在程序中设置,统一通过 xss 参数设置即可,或者使用默认值 0。
JVM 的内存划分大致如下图:
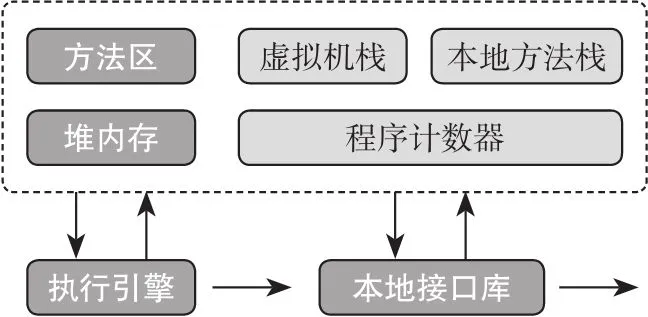
其中浅色的三块内存区域是每个线程独立拥有的,互相不干扰。
程序计数器 PC
无论什么语言,最终都是通过操作系统的控制总线发送机器指令给 CPU 执行。程序计数器就是用于存放当前线程接下来要执行的字节码指令、分支、循环、跳转、异常处理等。每一个时刻, CPU 的一个核心都只会处理一条指令,所以每个线程都需要有独立的程序计数器,用于记录各自的执行点,以便于 CPU 在切换上下文后恢复到上一次的执行点开始下一次执行,线程间互不干扰。
虚拟机栈
虚拟机栈和程序计数器类似,也是 线程私有 的,生命周期与线程相同,是在 JVM 运行时 创建的。在线程中,方法在执行的时候都会创建一个名为栈帧(stack frame)的数据结构,这个数据结构主要用于存放 局部变量表 、 操作栈 、 动态链接 、 方法出口 等信息。方法的调用过程对应着栈帧的弹栈和压栈的过程,所以递归深度越深,程序不断地压栈而迟迟不弹栈,虚拟机栈就会爆掉,发生 StackOverflowException 。每一个线程在创建的时候,JVM 都会为其创建对应的虚拟机栈,虚拟机栈的大小可以通过 -xss 来配置。

本地方法栈
Java 中提供了调用本地方法的接口,即 JNI (Java Native Interface) 也就是 C/C++ 程序,Java 为本地方法划分的内存区域便是本地方法区,这块内存区域有很高的自由度, JVM 规范也没有做过多的限制,完全由各个 JVM 厂商自己实现,同样是 线程私有 的内存区域。常见的用到了 JNI 的方法有,网络通信、文件操作的底层、String 的 intern 等。
堆内存
堆内存是 JVM 中最大的一块内存,被所有 线程共享 ,在运行期间创建的所有对象几乎都在这个区域,也是垃圾回收机制重点作用的区域,有时候又叫 GC 堆。堆内存还会被划分为更细的新生代、老年代两块,新生代还能细分,这些细分都是为了制定垃圾收集策略方便而设置的。
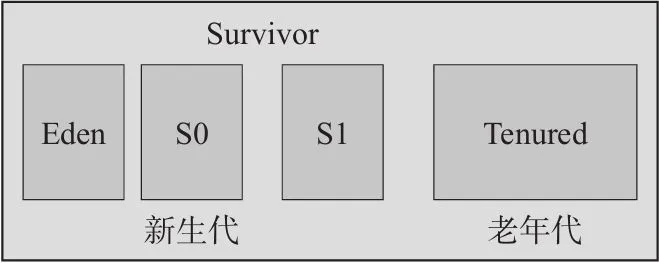
方法区
方法区是多个 线程共享 的区域,他的生命周期在线程之前,主要用于存储已经被虚拟机加载的类的信息、常量、静态变量、即时编译器 JIT 编译的代码等数据。在 Java 虚拟机规范中,将方法区划分为堆内存的一个逻辑分区,这意味着方法区也会发生 GC 。在 HotSpot JVM 中,方法区还会被细划分为持久代和代码缓存区,代码缓存区主要用于存储编译后的本地代码(和硬件相关)以及 JIT(Just In Time)编译器生成的代码,当然不同的 JVM 会有不同的实现。
JDK1.8 元空间
JDK 1.8 引入了元空间替代了方法区中的持久代(永久代),该区域同样在堆内存中,JVM 为每个类加载器分配一块内存块列表,进行线性分配,块的大小取决于类加载器的类型,sun/反射/代理对应的类加载器块会小一些,之前的版本会单独卸载回收某个类,而现在则是 GC 过程中发现某个类加载器已经具备回收的条件,则会将整个类加载器相关的元空间全部回收,这样就可以减少内存碎片,节省 GC 扫描和压缩的时间。
线程数量与内存的关系
从上面的介绍可知,线程的内存占用分为两块:私有的虚拟机栈和共享的堆内存。故一个 Java 进程占用的内存可以近似为 堆内存 + 线程数量 * 虚拟机栈。而 Java 每个进程的内存空间是有限的,比如 32 位 windows 操作系统允许最大进程内存为 2GB ,减去一部分的系统保留内存 ReservedOsMemory 。故根据以上关系可以得知,线程数量 = (最大地址空间 - JVM 堆内存 - ReservedOsMemory)/ ThreadStackSize (XSS)。
守护线程
守护线程一般用于处理一些后台工作,比如 JDK 的垃圾回收线程,正常情况下, JVM 进程会在没有普通线程工作的时候退出。因为守护线程是坚守到最后的线程,如果除了守护线程以外的线程都结束了,那么守护线程便无需再守护了,生命周期完成,可以随着 JVM 进程一起退出。
一般来说,父线程是正常线程,子线程也是正常线程,父线程是守护线程,子线程也会是守护线程。也可以使用 thread.setDaemon(true) 方法将线程设置为守护线程,该方法只能在线程启动之前调用,如果在线程死亡之后调用则会产生 IllegalThreadException 异常。
Thread API
sleep
线程休眠方法,该方法有两个重载方法:
sleep(long milis)sleep(long milis, int nanos)
休眠时间依赖于操作系统的调度,休眠期间线程不会放弃 monitor 锁的所有权。
public class ThreadSleep {
public static void main(String[] args) {
new Thread(() -> {
long startTIme = System.currentTimeMillis();
sleep(2_000L);
long endTime = System.currentTimeMillis();
System.out.println(String.format("Total spend %d ms", (endTime - startTIme)));
}).start();
long startTime = System.currentTimeMillis();
sleep(3_000L);
long endTime = System.currentTimeMillis();
System.out.println(String.format("Main thread total spedn %d ms", (endTime - startTime)));
}
private static void sleep(long ms) {
try {
Thread.sleep(ms);
} catch (InterruptedException e) {
System.out.println(e);
}
}
}上面的例子说明,每个线程的休眠都是独立的,Thread.sleep() 只会针对当前线程进入休眠状态。
使用 TimeUnit 替代 Thread.sleep() 这样可以省去时间单位换算的步骤。
yield
yield 用于提示调度器,该线程愿意主动放弃 CPU 资源,从 Running 状态 转为 Runnable 状态,如果 CPU 资源不紧张,调度器会忽略该提示。
JDK 1.5 之前的版本 yield 调用的是 sleep(0) 方法,但 yield 与 sleep 有着本质的不同。
yield使线程进入 RUNNABLE 阶段,sleep使线程进入 BLOCK 阶段;yield的提示不一定能保证线程休眠,sleep则一定会导致线程的休眠;- 一个线程
sleep另一个线程interrupt会捕获中断信号,而yield不会;
线程优先级
public final void setPriority(int newPriority) 为线程设置优先级;
public final int getPriority() 获取线程的优先级;
进程和线程都有优先级,理论上调度器会按照线程的优先级来执行,但实际上线程的优先级和 yield 一样,也是个提示性操作,实际的作用机制是:
- 如果是 root 用户,优先级的设置才会对操作系统起到提示作用;
- 如果 CPU 比较忙,高优先级的线程才有可能获得更多的资源,而对于 CPU 空闲时,优先级的高低几乎没有作用;
一般来说,不会主动设置线程的优先级,默认情况,线程的优先级继承自父线程的,如果设置线程的优先级大于 ThreadGroup 的优先级,线程的优先级会被设置成 ThreadGroup 的优先级。
获取线程 ID
public long getId() 获取线程的唯一 ID ,线程的 ID 在整个 JVM 进程中都是唯一的,并且从 0 开始逐次递增。由于 JVM 进程启动的时候会执行很多线程,所以轮到程序内的线程创建时,都不会是第一个线程了,一般拿不到 ID 为 0 的线程。
获取当前线程
public static Thread currentThread() 获取当前线程的引用。
设置线程上下文类加载器
public ClassLoader getContextClassLoader() 获取线程上下文的类加载器,如果修改线程上下文类加载器,默认和父类的类加载器一致;
public void setContextClassLoader() 设置线程的类加载器,可以打破双亲委托机制,是 Java 类加载器的后门;
线程中断
interupt() 方法的调用会使进入阻塞状态的线程中断,
以下方法会使线程进入阻塞状态:
- Object 的 wait 方法。
- Object 的 wait(long) 方法。
- Object 的 wait(long, int) 方法。
- Thread 的 sleep(long) 方法。
- Thread 的 sleep(long, int) 方法。
- Thread 的 join 方法。
- Thread 的 join(long) 方法。
- Thread 的 join(long, int) 方法。
- InterruptibleChannel 的 io 操作。
- Selector 的 wakeup 方法。
- 其他方法。
线程的中断 并不意味 着生命周期的结束,仅仅是线程的阻塞状态被打断了。线程阻塞状态被中断时会抛出一个 InterruptedException 异常。线程内有一个 interrupt flag 的标识,如果线程中断了,那么这个标识会被打开,如果线程是在被阻塞的时候中断的,那么这个标识反而会被清除。如果线程已经死亡了, interrupt() 的调用将会被忽略。
代码示例:
public class InterruptTest {
public static void main(String[] args) throws InterruptedException {
Thread thread = new Thread() {
@Override
public void run() {
while (true) {
try {
TimeUnit.MINUTES.sleep(1);
} catch (InterruptedException e) {
//ignore the exception
//here the interrupt flag will be clear.
System.out.printf("I am be interrupted ? %s\n", isInterrupted());
}
}
}
};
thread.start();
TimeUnit.MILLISECONDS.sleep(2);
System.out.printf("Thread is interrupted ? %s\n", thread.isInterrupted());
thread.interrupt(); // thread 正在执行阻塞方法 sleep() ,此时主线程调用 thread.interrupt() 使阻塞中断,线程抛出 InterruptedException ,捕获异常后发现 isInterrupted() 方法返回 false ,说明 interrupt() 复位了 interrupt flag 标识
System.out.printf("Thread is interrupted ? %s\n", thread.isInterrupted());
}
}isInterrupted() 方法用来判断线程是否被中断,这个方法仅仅判断 interrupt 标识是否被打开,并不会影响标识的状态。
interrupted() 是 静态方法 可以用于判断当前线程是否被中断,调用该方法会 擦除 线程的 interrupt 标识,如果当前线程被中断了,那么第一次调用该方法会返回 true 并立即擦除 interrupt 标识(置为 false),之后的调用都会返回 false 。
一般建议使用 interrupted() 检查线程是否被中断,因为 isInterrupted() 不会复位线程的 interrupt 标识,如果捕获到线程中断之后,不打算直接结束任务而是继续任务,那么复位 interrupt 标识为 false 以便于下次中断发生时,能够继续捕获,否则由于 isInterrupted() 不停返回 true ,任务将无法继续进行。
实际上,interrupted() 和 isInterrupted() 两个方法调用的都是同一个本地方法:
private native boolean isInterrupted(boolean ClearInterrupted);区别在于 isInterrupted() 方法传入的 ClearInterrupted 参数为 false 表示其不会复位 interrupt 标识,而 interrupted() 方法传入的参数为 true ,将复位 interrupt 标识。
如果线程在可中断方法执行之前就被中断了,那么等执行到可中断方法时,会立即中断,并抛出 InterruptedException 异常。
线程 join
Thread 的 join 方法和 sleep() 方法一样是一个可中断方法(能够捕获其他线程的 interrupt 操作,抛出 InterruptedException 并擦除线程的 interrupt 标识)。
三个 join 方法:
public final void join() throws InterruptedException
public final synchronized void join(long millis,int nanos) throws InterruptedException
public final synchronized void join(long millis) throws InterruptedExceptionjoin 某个线程 A ,使线程 B 等待线程 A 结束生命周期,或者到达指定的时间。在此期间,线程 B 是出于 BLOCKED 状态的。例如以下代码:
public class JoinTest {
public static void main(String[] args) throws InterruptedException {
//① 定义两个线程,并保存在threads中
List<Thread> threads = IntStream.range(1, 3)
.mapToObj(JoinTest::create).collect(toList());
//② 启动这两个线程
threads.forEach(Thread::start);
//③ 执行这两个线程的join方法
for (Thread thread : threads) {
thread.join();
}
//④ main线程循环输出
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "#" + i);
shortSleep();
}
}
//构造一个简单的线程,每个线程只是简单的循环输出
private static Thread create(int seq) {
return new Thread(() ->
{
for (int i = 0; i < 10; i++) {
System.out.println(Thread.currentThread().getName() + "#" + i);
shortSleep();
}
}, String.valueOf(seq));
}
private static void shortSleep() {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}main 线程先等待 thread-1 执行完毕(等待期间 thread-2 已经启动了),然后等待 thread-2 执行完毕,最后往下执行。对于已经结束生命周期的线程,调用其 join() 方法不会等待,直接往下执行。
线程关闭
正常关闭
- 线程正常运行结束;
- 捕获中断信号关闭线程;
数据竞争
多个线程同时读写一个变量会带来数据竞争的问题,如果不处理好读写的原子性,就会带来线程安全问题。
extend Thread 实现自己的线程时使用 static 变量(类变量)并不能保证线程安全,尽管按照直观理解,每个线程都是独立的实例,对于共享的类变量修改应该不像成员变量那样,各自操作各自的。
synchronized 关键字
synchronized 关键字实现了对共享变量的并发访问控制,防止数据不一致情况的出现。
其包括两条关键 JVM 指令: monitor enter 和 monitor exit 。
同步方法
public synchronized void sync() {
...
}同步代码块
private final Object MUTEX = new Object();
public void sync() {
synchronized( MUTEX) {
...
}
}错误使用
多线程锁不同实例
public static class Task implements Runnable {
private final Object MUTEX = new Object();
@Override
public void run() {
//...
synchronized (MUTEX)
{
//...
}
//...
}
}
public static void main(String[] args) {
for (int i = 0; i < 5; i++) {
new Thread(Task::new).start();
}
}上面代码新建了 5 个线程,但每个线程各自新建了一个 Task 实例,每个实例使用的 MUTEX 变量相互独立,引用都不一样,所以相当于每个线程锁了各自实例的 MUTEX 变量,达不到加锁的目的;